Table of Contents
GPU 기반 워크로드 운영이 어려운 이유
최근 몇 년 동안 Gen AI를 위한 MLOps 플랫폼을 개발하고 GPU 기반 AI 워크로드를 운영하고 있다. 처음에는 레퍼런스 하나 찾기가 어려웠지만 최근에는 주변에서도 자체적으로 LLM과 같은 GPU 기반 워크로드를 운영하는 사례가 많아지고 있음을 느끼고 있다.
특히 생성형 AI, LLM에대한 수요가 늘어나면서 GPU 기반 워크로드는 일부 조직에서만 사용하는 것이 아닌 회사의 주요한 관심을 받는 핵심 인프라가 되었다. (너무 비싸서 주목받는 것일지도..)
하지만 실제로 GPU 워크로드를 운영해보면 단순히 “GPU"라는 새로운 유형이 추가된 것이 아닌 기존과 다른 운영 설계와 접근법이 필요한 문제라는 것을 인식하게 된다.
이번에는 실제 업무를 수행하면서 GPU 기반 워크로드를 다룰 때 겪게 되는 어려움들을 정리해보았다.
1. GPU는 장애를 염두에 두고 설계해야한다. - 하드웨어 장애가 잦은 GPU
제일 먼저 생각해볼 것은 하드웨어 측면에서 GPU가 아주 복잡하다는 점이다. GPU 는 그래픽 처리와 같은 대용량 병렬 연산을 위해 설계된 만큼, 고집적 연산 유닛(SM-Streaming Multiprocessor)과 고대역폭 메모리(HBM)를 포함하고 있으며, CPU보다 훨씬 복잡한 하드웨어다. 하드웨어 레벨에서 GPU 사이의 통신(intra-connect)을 위한 NVLINK, 멀티 노드의 통신을 위한 RDMA 지원을 위한 IB / RoCE 등 추가적인 장치들과도 연결된다. 이런 복잡한 구조는 조금 더 잦은 장애로 이어진다. 거기다가 모델 학습과 같은 GPU Utilization 을 매우 높게 유지하는 워크로드를 실행하게 되면 하드웨어 측면에서 높은 발열이 발생하는데 이런 복잡한 하드웨어 구조에서 지속적으로 열이 발생하게 되면 그만큼 또 장애 발생 가능성이 높아지게 된다.
NVIDIA GPU에서는 이러한 오류를 보정하기 위한 ECC(Error Correcting Code) 기능이 존재하지만, 이것으로도 수정하지 못하는 다중 비트 오류(Uncorrectable)가 발생하기 때문에 데이터 손상, 나아가 시스템 중단(Xid 에러)이 발생하여 해당 GPU 노드를 물리적으로 재시작해야하는 경우도 잦다.
모델학습과 관련해서 메타(Meta)가 공개한 “The Llama 3 Herd of Models” 문서를 참고하면, LLaMA 405B 모델 트레이닝 사례를 확인할 수 있다. 여기에서 LLama 모델학습을 위해서 총 16,384개의 H100 GPU로 구성된 클러스터에서 54일동안 트레이닝 작업을 진행했는데 총 419번의 예상치 못한 중단 사례가 발생했고 그 중에서 78%는 하드웨어 이슈였으며 이중 58.7%가 GPU, 8.4%가 네트워크 이슈였다고 한다. 단순히 계산하면 3시간에 한번꼴로 장애가 발생했다는 것을 알 수 있다. 이는 CPU 의 경우보다 GPU 관련 장애 비율이 압도적으로 높았다는 점을 확인할 수 있고, 대규모 GPU 클러스터의 MTBF(Mean Time Between Failure)가 우리가 직관적으로 기대하는 것보다 훨씬 짧을 수 있음을 의미한다.

즉, GPU 워크로드 운영에서는 “장애가 발생하지 않기를 기대하는 것"이 아니라, 언제든지 장애가 발생할 수 있다는 가정 하에 복구 전략과 모니터링 시스템을 갖추는 것이 필요하다. 그렇지 않으면 안정적인 워크로드 운영이 불가능하고 잦은 장애로 인해서 워크로드가 중단되는 일이 잦아질 수 밖에 없다.
따라서 GPU 워크로드를 운영할 때에는 다음의 내용들이 같이 고민되어야 한다.
- 학습의 경우 checkpoint 를 적절한 주기로 관리하도록 설계하여 장애에 대한 민감도를 낮추는 방법
- DCGM 및 Xid 기반 GPU 헬스체크
- 실패를 전제로 하여 job 이 재시도 될 수 있는 정책 설계
결국 GPU 기반 워크로드 운영은 **“장애를 막는 것”**이 아니라 장애의 영향을 최소화 할 수 있도록 설계하는 것이다.
2. 기존 워크로드와 다른 LLM 시대의 AI 워크로드
LLM 시대의 GPU 워크로드는 기존의 CPU 기반 서비스 워크로드와 근본적으로 다른 특징들을 가지고 있다.
2-1 추론 워크로드 - GPU는 CPU처럼 스케일링 되지 않는다.
먼저 추론 워크로드를 생각해보면 다음과 같다. 기존의 웹 서비스나 API 서버-CPU 워크로드는 요청/응답이 수 밀리초에서 수 초 이내에 종료되는 것이 일반적이었다. 반면 LLM 추론 워크로드는 하나의 요청이 수십 초에서 길게는 수 분 동안 GPU를 점유할 수도 있다. 이는 단순한 오토스케일링이나 리퀘스트 수 기반 부하 제어로는 대응하기 어려운 특성이다.
스케일링 측면에서 CPU 워크로드에서는 cpu 가 80% 이상일때 replica 를 늘리거나 줄이는 작업이 용이하지만, GPU 워크로드에서는 GPU Utilization 이 CPU와 달리 선형적으로 증가하지 않는다. Prefill 단계에서는 급격히 상승하고, Decode 단계에서는 Token 생성 속도에 따라 변동한다.
다음의 특정 추론 워크로드에서는 GPU Utilization이 100% 아니면 0% 의 로드를 보여주어서 특정 threshold 를 기준으로 스케일링 할 수가 없었다.
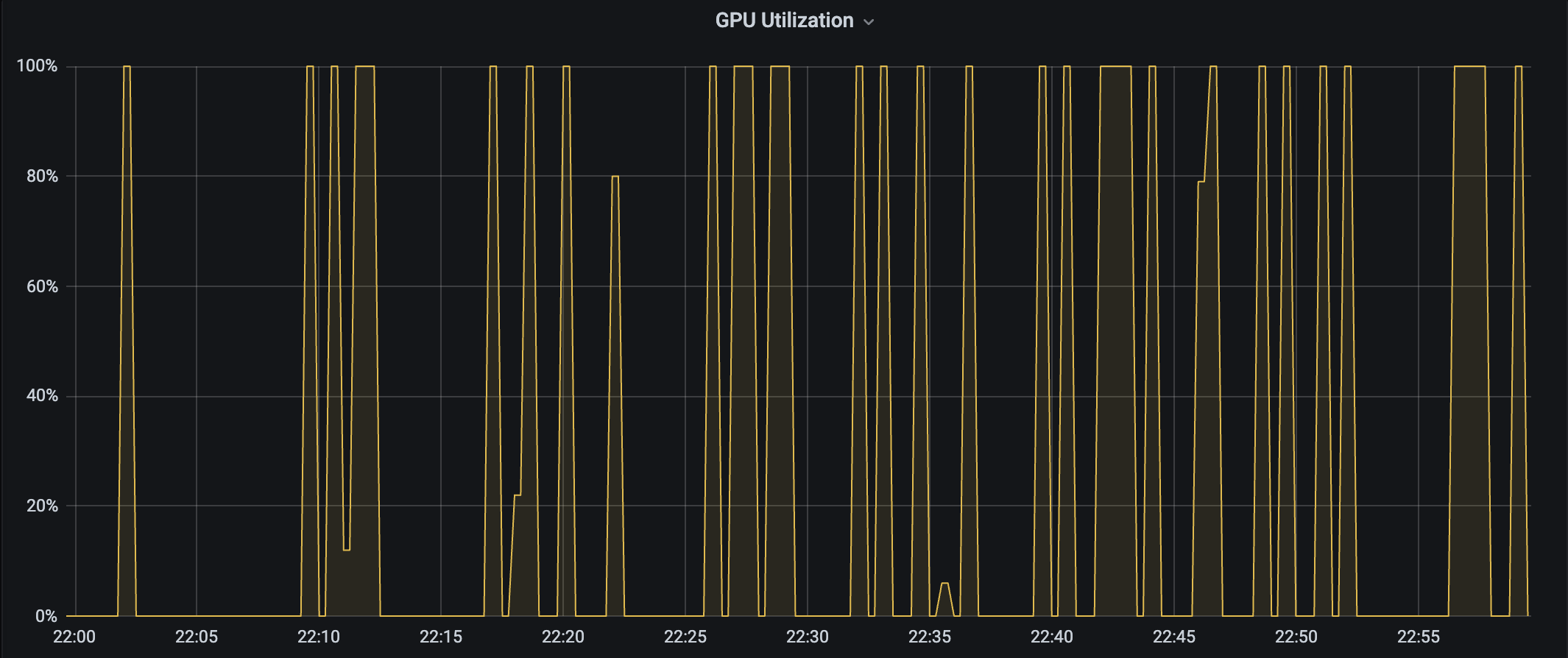
따라서 GPU load 기반의 load balancing, request queue 기반 scaling, heterogeneous gpu workload 와 smart routing 의 결합등 다양한 방식의 대안을 고려해야한다. 결국 GPU 추론 워크로드는 단순 compute 문제가 아니라 메모리·대기열·토큰 길이의 상호작용을 고려한 오토스케일링 방식이 필요하다.
2-2 학습 워크로드 - 일부 작업이 실패할 수 있다는 전제가 필요하다
학습 워크로드는 더욱 복잡하다. 단일 컨테이너가 아닌 다수의 컨테이너가 동시에 여러 노드에 스케줄되어야 하며, 하나라도 실패하면 전체 작업이 무의미해질 수 있다. 이로 인해 JobSet, Gang Scheduling, Leader-Worker 구조와 같은 새로운 워크로드 유형이 필요해졌고, 이는 운영을 한 단계 더 복잡하게 만든다.
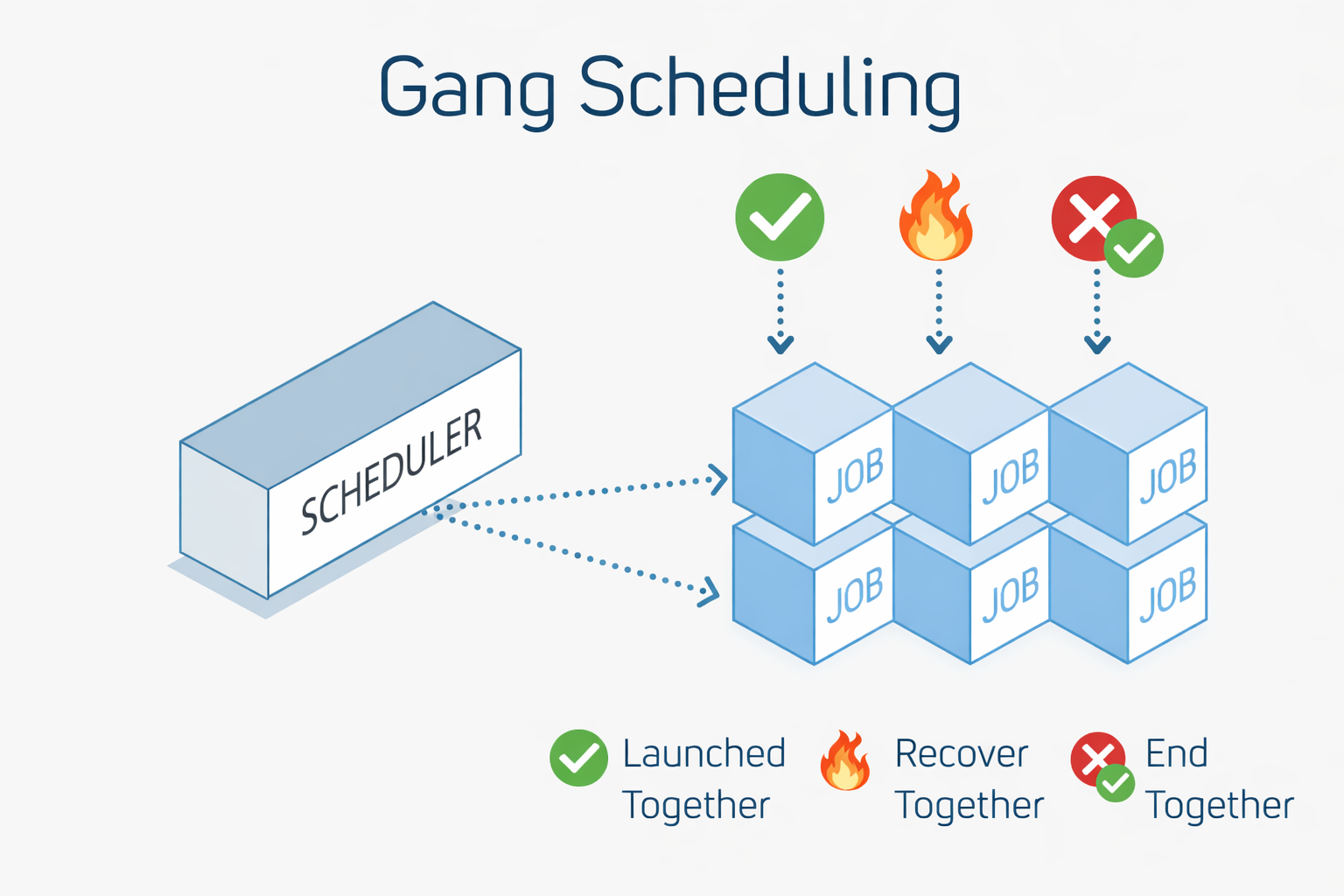
즉 GPU 학습 워크로드는 분산시스템의 설계를 고민하게 만든다.
결과적으로 GPU 워크로드는 단순히 “리소스를 많이 쓰는 워크로드"가 아니라, 기존 운영과는 다른 새로운 유형의 워크로드라고 볼 수 있다.
3. GPU 워크로드 생태계는 아직 성숙하지 않다
그럼 이런 새로운 유형의 워크로드를 지원하는 생태계는 어떨까?
오랜기간 동안 CPU와 Memory는 주요하게 관리되는 리소스였고, 그만큼 운영 및 오케스트레이션 기술도 충분히 안정화 되어 있다. 그에 반해 GPU는 비교적 최근에야 범용 워크로드로 관리하고 있기 때문에, Kubernetes와 같은 오케스트레이션 도구에서도 여전히 GPU는 특별한 자원으로 관리되고 있다.
3-1 GPU 워크로드를 위한 K8S 스케줄링 고민
fragmentation
GPU 노드위에 워크로드는 단순한 스케줄링 대상이 아니라 파편화 문제를 고민해야한다.
다음과 같이 노드에 GPU 자원이 각각 8 GPU 씩 가용 할때, 워크로드의 GPU size 가 각기 다를 수 있다.
이 경우 기본적으로 제공되는 K8S Default scheduler 를 사용하면 배치 전략이 LeastAllocated 이기 때문에
배치 전략을 그대로 사용하면 리소스를 클러스터 전체에 골고루 분산시켜 특정 노드의 부하를 방지하려고 한다.
문제는 이렇게 되면 아래 그림과 같이 전체 클러스터에 논리적 레벨에서는 가용한 자원이 남아 있더라도, 물리적 레벨에서 가용한 노드가 존재하지 않는 상황이 발생할 수 있다.
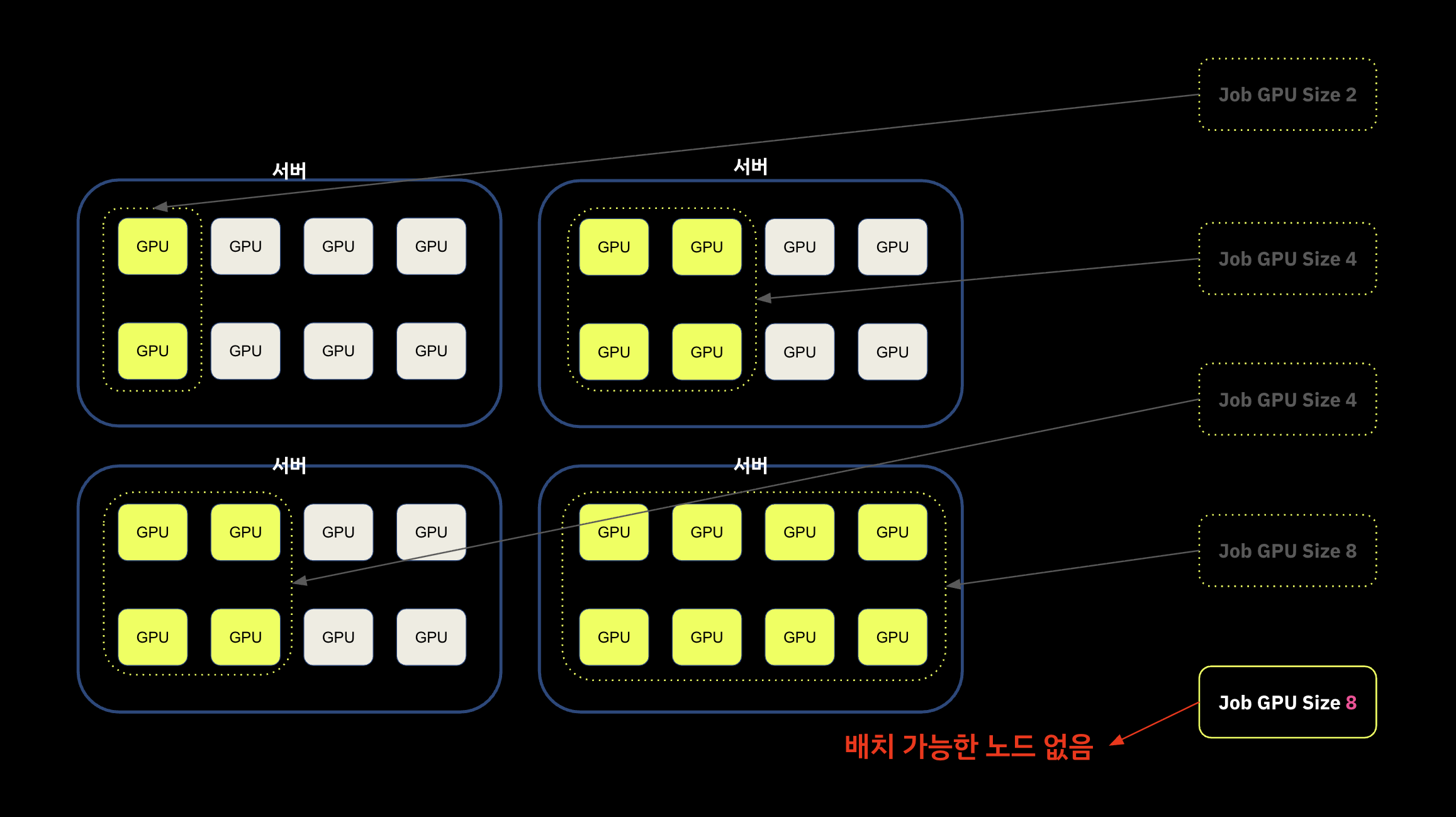
Default scheduler는 CPU 중심 철학 위에 설계되었기 때문에, GPU 환경에서는 예상치 못한 파편화를 유발할 수 있다. 대신 custom scheduler 를 사용하여 MostAllocated 전략을 사용할지에 대한 고민이 필요하다.
여기에 더해서 NVLink, MIG, Inter-connect bandwidth 와 결합하면 단순히 bin-packing 문제가 아니라 하드웨어 레벨에서의 topology 를 고려한 스케줄링 고민이 필요하다.
노드 단위 장애 전파 최소화 - Training & Inference
파편화에 대한 문제와 더불어서 고민할 것은 GPU 가 하드웨어 장애가 잦다보니, 이에 대한 안정성을 높이기 위해서 학습용 워크로드와, 추론용 워크로드를 분리하는 방식을 고민해야한다는 점이다. 단일 노드에 학습 워크로드와 추론 워크로드를 함께 배치하면 장애 비율이 상대적으로 높은 학습 워크로드의 특성상 추론 워크로드에 영향을 줄 수 있고, 이 때문에 안정성이 중요한 추론 워크로드가 빈번하게 영향을 받을 수 있다.
두 가지 워크로드는 운영 목표 자체가 다른데, 학습 워크로드는 처리량 중심 워크로드이고, 추론 워크로드는 latency + availability 중심 워크로드이다. 따라서 노드 레벨에서 두가지 워크로드를 같이 운영하기 보다 노드 단위에서 학습 워크로드와, 추론 워크로드를 분리하는 스케줄링 전략에 대해서도 고민이 필요하며 이 것이 SLO 분리 전략 관점에서 고려되어야 한다.
요약하자면 K8S 측면에서 CPU 중심으로 설계된 기존 리소스 관리 모델을 그대로 적용하기 어렵고, GPU 전용 스케줄링 정책, 쿼터 모델, 격리 전략을 별도로 고민해야 한다. 많은 조직에서 GPU 운영이 어려운 이유는 단순히 “GPU가 비싸서"가 아니라, 이를 안정적으로 다룰 수 있는 운영 패턴이 아직 표준화되지 않았기 때문이기도 하다.
4. GPU 리소스 거버넌스 - 조직 차원에서 희소 자원을 어떻게 fair sharing 할 것인가?
Gen AI를 위한 GPU 는 아주 비싼 자원이다. 그래픽 카드 하나를 구매하는데 몇천만원이 필요하고, NVLINK, IB 와 같은 네트워크 장비까지 고려하면 노드 하나당 몇억 수준의 비용이 발생한다. 이렇게 비용이 많이 드는 자원을 조직내에서 충분히 확보하기란 쉽지 않은 일이다.
이 때문에 발생하는 문제는 단순한 비용에서 그치는 것이 아니라,
- 충분한 실험 기회의 부족
- 엔지니어링 경험의 편중
- 조직 내 자원 분배 갈등 으로 이어진다.
결국 GPU 클러스터 운영은 기술 문제뿐만 아니라 조직 내 자원 분배 철학의 문제이기도 하다. 희소자원의 공정한 배분 문제를 어떻게 해결할것인가 정책적인 고민이 함께 필요하다.
5. 고비용 하드웨어가 만드는 경험의 장벽 - 개인의 역량 향상의 어려움
그리고 또 하나를 고려해보자면 경험의 장벽이 있다는 점을 고려해야한다. GPU는 매우 고가의 자원이다. 최신 GPU 한 장의 가격은 중소 규모 팀이나 스타트업 입장에서는 쉽게 접근하기 어려운 수준이고, 대규모 클러스터를 직접 운영할 수 있는 조직은 더욱 제한적이다. 이로 인해 엔지니어 개인의 관점에서는 GPU 워크로드를 실제로 운영해보고 실패를 경험해볼 기회 자체가 많지 않다. CPU 기반 시스템에서는 비교적 쉽게 실험하고 개선할 수 있었던 것들이, GPU 환경에서는 비용과 리스크 때문에 보수적으로 접근하게 되기 때문이다.
이 때문에 이러한 자원을 관리하고 운영해본 엔지니어 풀 자체가 적을 수 밖에 없고 이것이 엔지니어 개인 입장에서 경험의 장벽으로 다가온다. 자원에 대한 접근성의 문제는 결국 엔지니어 개인의 경험 격차로 이어지고, GPU 워크로드 운영이 “소수의 조직과 엔지니어만의 영역"으로 남게 되는 구조를 만들기도 한다.
6. 발전중인 생태계
6-1 NVIDIA 의 대체제
NVIDIA 이외에도 다양한 벤더사에서 GPU에 대항하는 하드웨어를 개발하고 있다. 물론 아직은 NVIDIA의 GPU 가 가장 선호되지만, 다양한 대체제가 계속 발전하고 있다.
- Google 의 TPU
- Intel 의 XPU
- AMD 의 ROCm
- Furiosa, rebellions 의 NPU
물론 이를 지원하기 위한 오케스트레이션 레벨에서의 고민이 추가되기도 한다 :)
K8S 클러스터에서 NVIDIA-GPU, Intel XPU, AMD ROCm 디바이스를 지원하기 위해서는 기본적으로 Device Plugin 을 추가로 적용해야하는 구조이다. 각각의 벤더사에서 제공하는 device plugin 이 각기 다르고, 여기에서 생성한 metric 또한 조금씩 차이가 있다. Device Plugin 도 단순히
CPU, Memory 와는 다른 추가적인 디바이스의 인식에 가깝기 때문에 RDMA, 네크워크, 스토리지와 결합된 경우 자원이 유기적으로 연결되어 있다고 보기 어렵다.
6-2 K8S 의 AI 워크로드 대응
최근의 CNCF 에서 발표되는 K8S 발표자료를 보자면 Youtube Channel AI 워크로드 지원과 관련된 주제가 늘어났다는 것을 느낄 수 있다. 그만큼 생태계가 빠르게 발전하고 있다. 최근에 관심있게 보고 있는 주제들은 다음과 같고, 개별 주제들도 조금만 깊게 들어가면 공부할게 한가득이다.
-
Device Plugin (정적 할당의 한계) 극복을 위한 동적 자원 관리 DRA
-
여러개의 Job을 한번에 구동하기 위한 JobSet
-
1.35 에서 alpha 기능으로 추가된 Native 하게 Gang Scheduling 을 구동하기 위한 준비 Gang Scheduling
-
분산 추론등 고급 inference 를 위한 llm-d
-
Gen AI 를 위한 AI Gateway 기술, 대표적으로는 Envoy AI Gateway
이러한 발전을 보고 있으면 빠르게 생태계가 변화하고 있으며 이를 통해서 그동안의 제약들을 극복하려는 움직임들을 느낄 수 있다. 불과 3년전에 ChatGPT 4 가 출시되면서 본격적으로 Gen AI 에 대한 인식이 시작된것을 생각하면 앞으로 또 얼마나 새로운 고민과 발전사항이 다가올지 기대와 우려가 공존한다.
물론 대규모 학습을 위한 워크로드 컨트롤은 아직까지는 Slurm 이 선호되는게 현실이다.
K8S 생태계는 점점 GPU를 1급 자원으로 끌어올리려는 방향으로 발전하고 있다.
마무리하며
GPU 기반 워크로드 운영이 어려운 이유는 하나의 문제가 아니다. 하드웨어의 불안정성, LLM 시대의 새로운 워크로드 특성, 희소 자원의 배분 정책, 아직은 발전이 더 필요한 워크로드 관리 생태계, 그리고 고비용으로 인한 경험의 장벽이 복합적으로 얽혀 있다. 각각의 주제만 하더라도 조금 만 더 깊게 들어가면 고민할게 많아지기 때문에 전체를 한번에 다 아우르기 어렵고, 물리적으로 많은 시간이 필요하다고 느끼고 있다.
GPU 운영을 “더 높은 메모리, 더 빠른 연산"의 관점으로 접근하기 보다 “불완전한 시스템을 지속 가능하게 만드는 방법"의 관점에서 접근하는게 바람직하다.
결국 GPU 워크로드는 ‘고장 가능성이 높은 하드웨어 위에서, 긴 실행 시간을 가진 분산 작업을, 파편화된 자원 환경에서 안정적으로 돌리는 문제’ 이고, 이를 극복하는 과정은 단순히 기술의 선택 문제가 아니라 운영 철학과 설계가 함께 고민해야하는 문제이다.
이번에는 GPU 워크로드를 다루는 일이 “왜 어려운지"를 정리해 보았는데, 기회가 될 때 이러한 어려움을 조직과 플랫폼 차원에서 어떻게 완화할 수 있을지에 대해서도 포스팅해보겠다.
comments powered by Disqus