Table of Contents
비용효율적인 LLM Inference 환경을 위한 AIBrix
LLM(Large Language Model) 활용한 서비스를 구축하려고 하면 다양한 비용에 대한 고민을 할 수 밖에 없다. 안정적인 추론(Inference) 환경을 위해서 고비용의 GPU 인스턴스를 마련하는 것도 일이지만, 안정적인 추론환경을 제공하는 것도 쉽지 않다. 대부분 K8S 클러스터를 기반으로 이런 환경들을 구성하는데 이쪽 분야가 빠르게 발전하고 있다보니 아직 표준이라고 할만한 프레임워크도 없어서 여러가지 시행착오를 거치고있다.
그러던중 vLLM 에서 소개한 AIBrix를 알게되어 이를 간단하게 살펴보았다. 특히 내가 눈여겨 보고 있는 부분은 추론 성능을 극대화 하기 위한 분산 KV Cache 부분인데, 이부분은 내용이 방대해서 별도의 포스트를 추가하기로 하고 오늘은 간단하게 개념만 살펴보았다.
비싼 GPU 인스턴스
대규모 LLM 모델의 추론환경을 구성하려면 GPU 인스턴스의 비용도 높고, 만약 자체 모델을 준비한다면 모델 학습 비용또한 적지 않다.
-
AWS 도쿄리전 기준 H200 8 GPU 1 Node (p5.48xlarge) 비용은 시간당 $123.19496 이다.
-
이를 한달 기준으로 하면 $88700.3712 / 환율 1450으로 계산하면 원화 기준 한달 요금 128,615,538.24 원 (약 1.28억)이다.
-
AWS 도쿄리전 기준 A100 8 GPU 1 Node (p4d.24xlarge) 비용은 시간당 $44.92215 이다.
-
이를 한달 기준으로 하면 $32343.948 / 환율 1450으로 계산하면 원화 기준 한달 요금 46,898,724.6 원 (약 4700만원)이다.
-
Llama 3.3 70B 모델을 구동하려면 A100 4 GPU가 필요하다. p4d.24xlarge 1 Node 에 2 Replica 만 구동가능하다는 의미이다.
이 때문에 추론을 서빙하면서 비용을 절감하기 위한 노력들이 다양하게 이어진다.
vLLM
vLLM은 오픈소스로 다양한 모델들에 대한 추론(Inference)환경을 제공해주는 서빙 라이브러리다. GPU 메모리 오버헤드를 줄이는 “PagedAttention” 덕분에 기본적인 Hugging Face 파이프라인보다 훨씬 높은 성능(Accuracy 가 아닌 Transaction Per Second / Token Per Secode)을 보여준다.
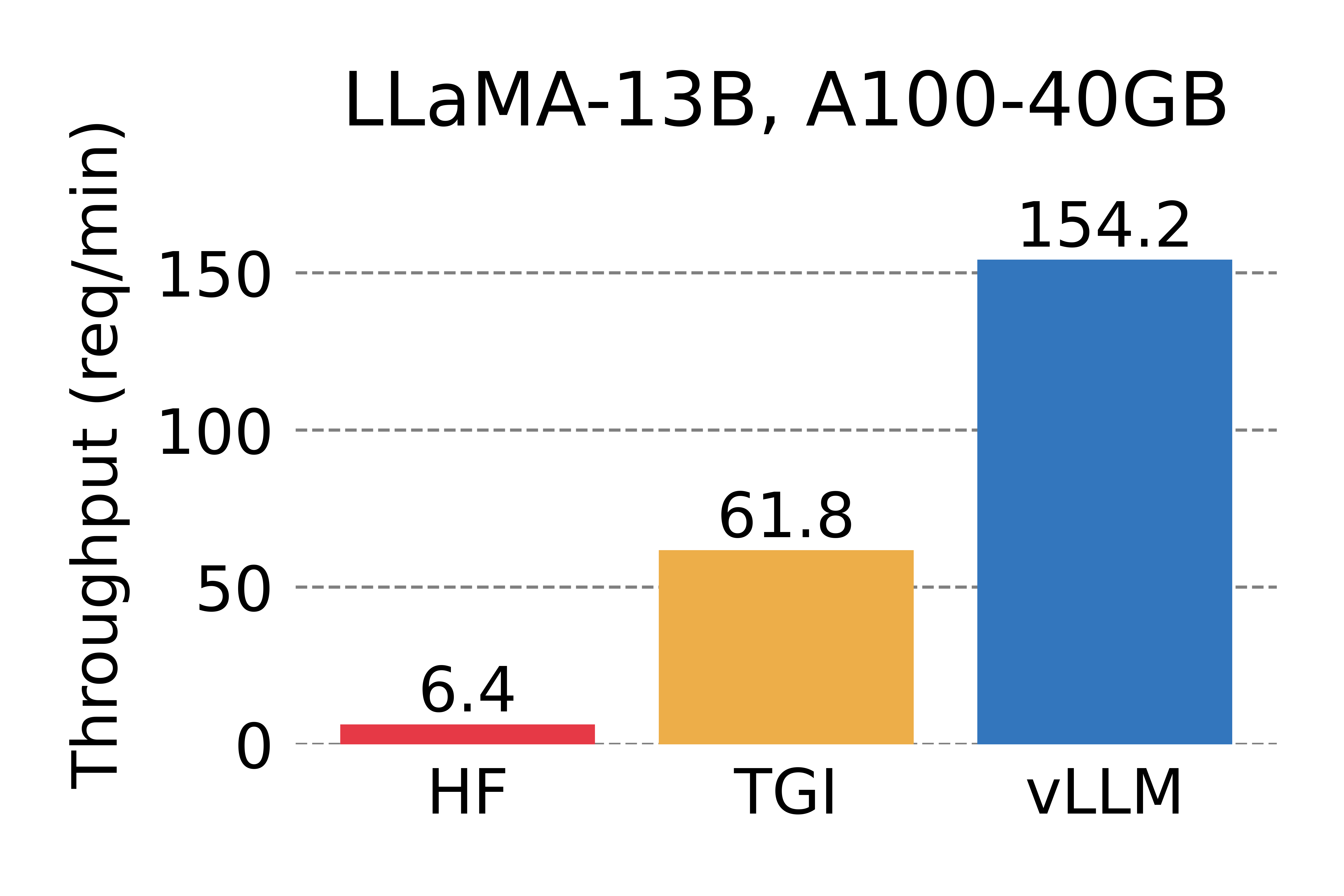
오픈소스 프로젝트로 매우 빠른 버전업이 진행중이고, 신규 모델들에 대한 번들을 제공하고 있어서 누구나 쉽게 모델 추론 환경을 구성할 수 있게 도와준다.
그래서 일단 가장 먼저 vLLM으로 추론 환경을 구성하고, 만약 필요하다면 추가적으로 TensorRT-LLM과 같은 NVIDIA에서 제공해주는 서빙 프레임워크를 사용해서 최적화를 추가로 진행하기도 한다.
하지만 대규모 LLM 추론 환경을 구성하려면 vLLM을 단일 노드에서 구동하는 것만으로는 부족함이 있다.
AIBrix
AIBrix는 클라우드 네이티브 기반의 오픈소스 프레임워크로, 대규모 LLM 배포를 최적화하고 간단하게 제공하는 것을 목표로 한다. ByteDance에서 vLLM을 사용하는 아키첵처를 AIBrix 라는 이름으로 오픈한 것으로 보인다.
쉽게 말해, AIBrix는 K8S 환경에서 LLM 추론 서버를 효율적으로 운영하기 위해 필요한 다양한 기능들을 제공하는 하나의 통합 솔루션이다.
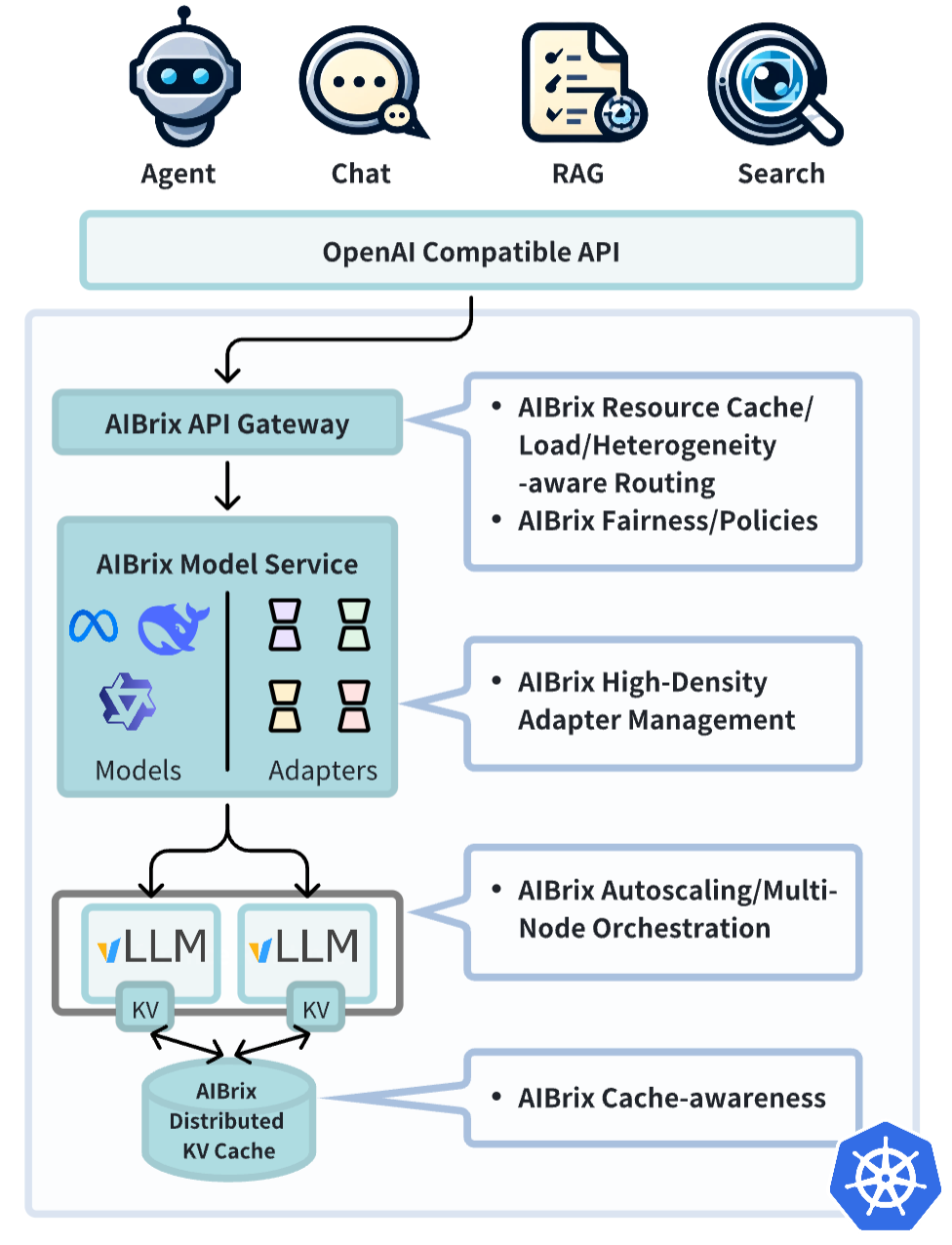
주요 기능
주요 기능은 다음과 같다.
- 고밀도 LoRA 관리 : LoRA 레이어를 사용하는 경우 이를 손쉽게 관리할 수 있게 도와준다.
- LLM 게이트웨이 및 라우팅 : 여러 모델에 대한 게이트웨이와 라우딩을 제공한다. 오픈 AI API 처름 다양한 모델들을 서빙하는 경우 필요하다.
- LLM 앱 맞춤형 오토스케일러 : CPU 워크로드와 다른 LLM 특유의 실시간 수요에 따라 추론 리소스를 동적으로 확장한다.
- 통합 AI 런타임 : 표준화된 메트릭 관리, 모델 다운로드 및 관리를 가능하게 하는 사이드카 제공
- 분산 추론 : 여러 노드에서 대규모 작업 부하를 처리할 수 있는 확장 기능 제공
- 분산형 KV 캐시 : 대용량, 여러 엔진 간 KV 재사용이 가능하게 한다. (이것 때문에 살펴보기 시작했다.)
- 비용 효율적인 이기종 서비스 : SLO 보장을 통해 혼합 GPU 추론을 활성화하여 비용 절감
- GPU 하드웨어 오류 감지 : GPU 하드웨어 문제 감지
이렇게만 보면 만능 솔루션으로 보이지만, 아직은 따끈따끈한(?) 0.2.1 버전이다. 그래서 가볍게만 둘러보기만 했고, 관심있는 분산형 KV 캐시 부분은 좀 더 깊게 파보기로 했다.
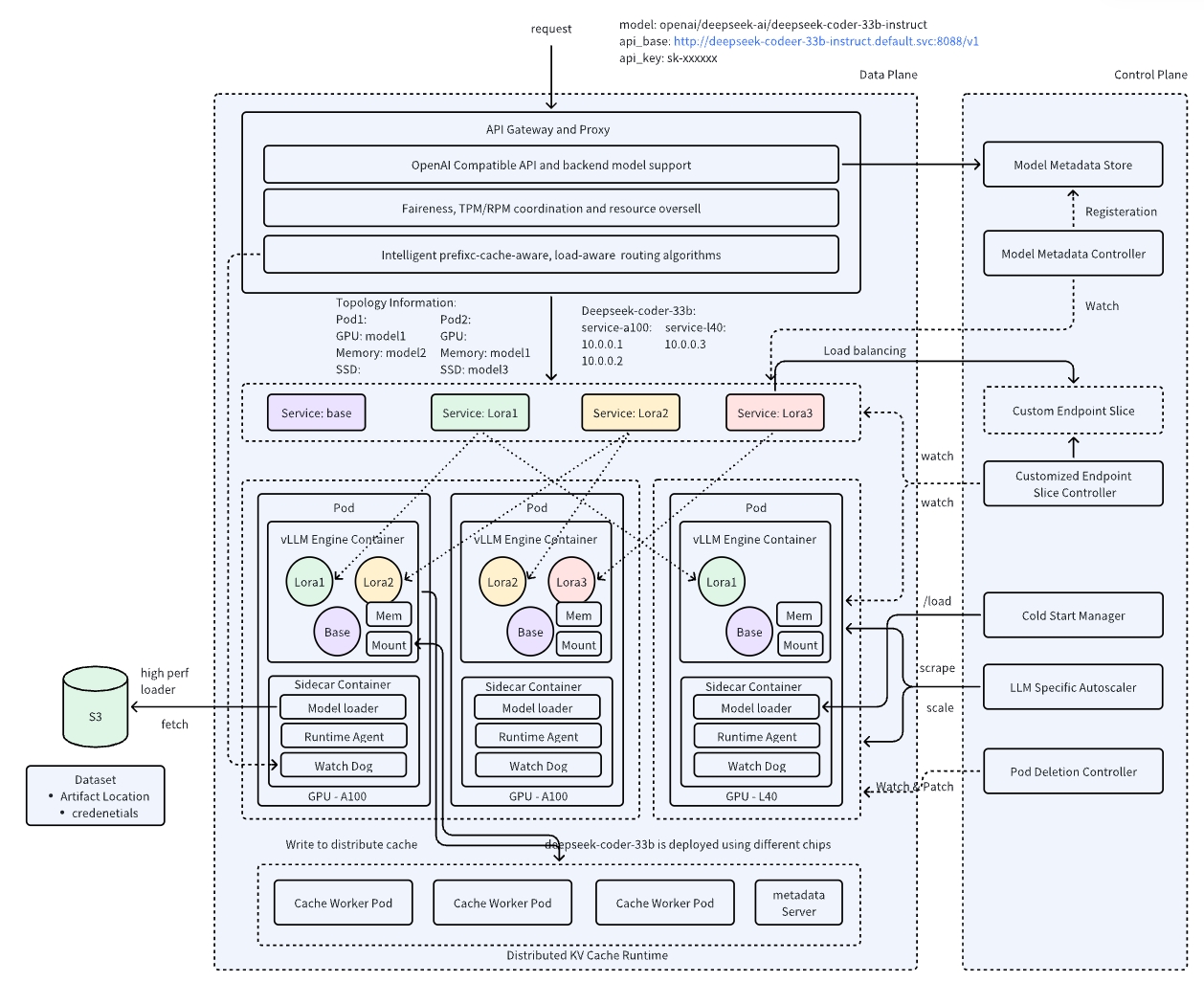
KV Cache
Transformer 아키텍처 기반의 LLM은 텍스트를 생성할 때 이전 토큰들의 정보를 기억하기 위해 KV(Key-Value) Cache를 사용한다.
특히 챗봇과 같이 이전 대화 내용을 기억해야 하는 다중 턴(multi-turn) 애플리케이션에서는 유사한 토큰 시퀀스가 반복되어 불필요한 연산이 발생하고, 이는 리소스 낭비와 처리량 감소로 이어질 수 있다.
이러한 문제를 해결하기 위해서 AIBrix 에서는 이 KV Cache 를 위한 분산 KV Cache을 제공한다.
- 고용량, 노드간 KV Cache 재사용: 여러 노드에 KV 캐시를 분산하여 저장하고 공유할 수 있도록 기능을 제공한다.
- 네트워크 및 메모리 효율성 최적화: 자주 사용되는(hot) KV 텐서를 우선적으로 유지하고, 메타데이터 업데이트를 비동기로 수행하여 오버헤드를 최소화한다. 그리고 캐시와 vLLM 워크로드를 동일한 노드에 배치해 share memory 기반의 빠른 데이터 교환을 지원한다.
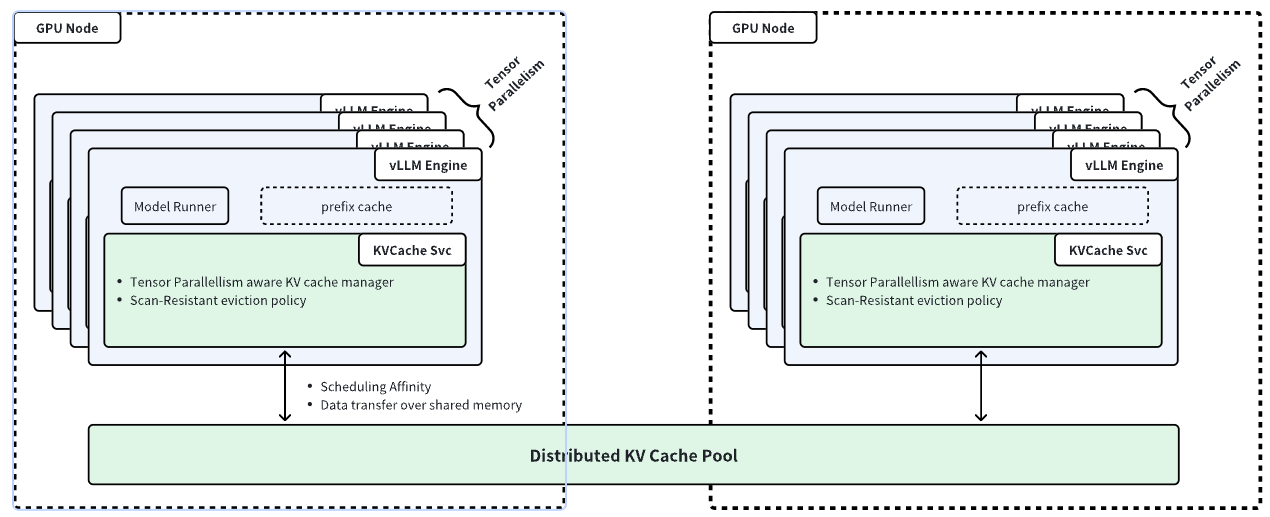
동일한 노드에 배치하기 위해서 사이드카 형태로 개별 GPU 노드에 셋업되며 그 기반은 vineyard 라는 솔루션을 커스텀해서 사용하고 있는 것으로 보인다. (그리고 또 그 vineyard는 캐시 스토리지로 redis를 사용하는 것으로 보인다.)
성능 향상 효과
실험 결과에 따르면 분산 KV 캐시는 vLLM의 기본 캐싱 방식과 함께 사용할 때 최대 처리량이 약 50% 증가하며, 평균 및 P99 TTFT(Time To First Token)가 각각 약 60%, 70% 감소하는 성능 향상이 있었다고 한다.
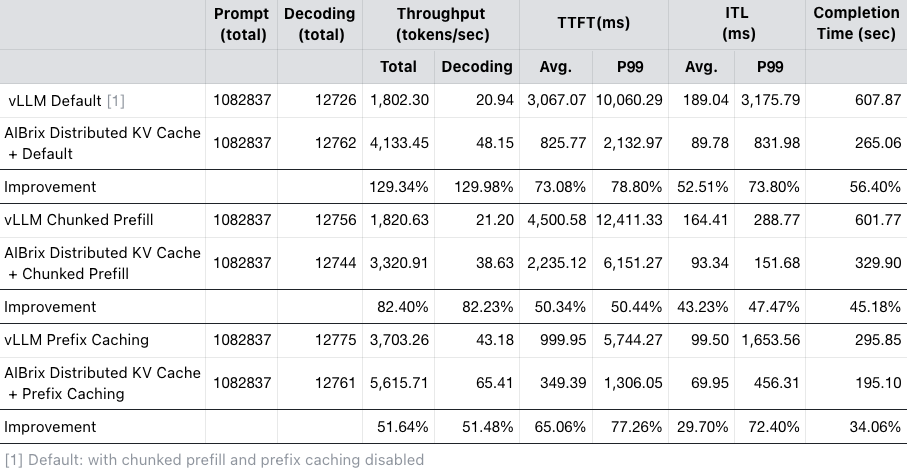
요약하자면, AIBrix의 분산 KV Cache는 LLM 추론 과정에서 발생하는 중복 연산을 줄이고 메모리 효율성을 높여, 처리량 증가와 지연 시간 감소를 동시에 달성하는 핵심 기술이다.
설치 방법
install
# 의존 컴포넌트 설치
# envoy 와 kuberay가 설치된다.
# 'aibrix-system' 라는 namespace 가 추가된다.
kubectl create -f https://github.com/vllm-project/aibrix/releases/download/v0.2.1/aibrix-dependency-v0.2.1.yaml
# aibrix 컴포넌트 설치
# aibrix operator 와 각종 플러그인 그리고 redis 가 설치된다.
kubectl create -f https://github.com/vllm-project/aibrix/releases/download/v0.2.1/aibrix-core-v0.2.1.yaml
기본 모델 배포
deepseek 에서 제공하는 llama 8b 증류 모델을 구동해본다. 최소한 A100 40G 이상 GPU 노드가 필요하다.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
model.aibrix.ai/name: deepseek-r1-distill-llama-8b # Note: The label value `model.aibrix.ai/name` here must match with the service name.
model.aibrix.ai/port: "8000"
name: deepseek-r1-distill-llama-8b
namespace: default
spec:
replicas: 1
selector:
matchLabels:
model.aibrix.ai/name: deepseek-r1-distill-llama-8b
template:
metadata:
labels:
model.aibrix.ai/name: deepseek-r1-distill-llama-8b
spec:
containers:
- command:
- python3
- -m
- vllm.entrypoints.openai.api_server
- --host
- "0.0.0.0"
- --port
- "8000"
- --uvicorn-log-level
- warning
- --model
- deepseek-ai/DeepSeek-R1-Distill-Llama-8B
- --served-model-name
# Note: The `--served-model-name` argument value must also match the Service name and the Deployment label `model.aibrix.ai/name`
- deepseek-r1-distill-llama-8b
- --max-model-len
- "12288" # 24k length, this is to avoid "The model's max seq len (131072) is larger than the maximum number of tokens that can be stored in KV cache" issue.
image: vllm/vllm-openai:v0.7.1
imagePullPolicy: IfNotPresent
name: vllm-openai
ports:
- containerPort: 8000
protocol: TCP
resources:
limits:
nvidia.com/gpu: "1"
requests:
nvidia.com/gpu: "1"
livenessProbe:
httpGet:
path: /health
port: 8000
scheme: HTTP
failureThreshold: 3
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 1
readinessProbe:
httpGet:
path: /health
port: 8000
scheme: HTTP
failureThreshold: 5
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 1
startupProbe:
httpGet:
path: /health
port: 8000
scheme: HTTP
failureThreshold: 30
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 1
---
apiVersion: v1
kind: Service
metadata:
labels:
model.aibrix.ai/name: deepseek-r1-distill-llama-8b
prometheus-discovery: "true"
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "8080"
name: deepseek-r1-distill-llama-8b # Note: The Service name must match the label value `model.aibrix.ai/name` in the Deployment
namespace: default
spec:
ports:
- name: serve
port: 8000
protocol: TCP
targetPort: 8000
- name: http
port: 8080
protocol: TCP
targetPort: 8080
selector:
model.aibrix.ai/name: deepseek-r1-distill-llama-8b
type: ClusterIP
모델 gateway 호출
# kubectl 포트 포워딩으로 해당 서비스 접근
kubectl -n envoy-gateway-system port-forward service/envoy-aibrix-system-aibrix-ak-6n54f 8888:80 &
ENDPOINT="localhost:8888"
# curl 호출
curl -X "POST" "http://localhost:8888/v1/chat/completions" \
-H 'Content-Type: application/json' \
-d $'{
"model": "deepseek-r1-distill-llama-8b",
"temperature": 0.7,
"messages": [
{
"content": "안녕하세요!",
"role": "user"
}
]
}'
# 응답
{
"id": "chatcmpl-82418164f0d24c60bf6ef8ad763111b6",
"object": "chat.completion",
"created": 1742809954,
"model": "deepseek-r1-distill-llama-8b",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "안녕하세요! 반가워요! 저는 사용자와 대화하는 인공지능입니다. 오늘은 어떻게 도와드릴까요?",
"tool_calls": []
},
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null
}
],
"usage": {
"prompt_tokens": 38,
"total_tokens": 69,
"completion_tokens": 31,
"prompt_tokens_details": null
},
"prompt_logprobs": null
}
마치며
AIBrix는 K8S 환경에서 대규모 LLM 추론 환경을 구성하고 운영하고자 하는 MLOps 엔지니어에게 적합한 통합 솔루션이다. 특히 Vineyard 기반의 분산 KV Cache는 LLM 기반 서비스의 성능과 효율성을 획기적으로 개선할 수 있는 기능이라 많은 분석이 필요해보인다.
추론은 GPU / Model / Serving 환경 3가지를 잘 조합해야 적절한 성능이 나온다. 개인적으로 많이 사용하는 vLLM 에서 이런 통합 솔루션을 제공해줘서 연구해볼거리가 늘어나 너무나 기쁘고(?!) 고마운 마음이다.
당장은 설치하는 것만 진행해보았지만(이것도 일이 작지 않다..), vineyard 연결 부분과 실제 추론의 성능 향상 효과를 측정하기 위한 평가 데이터셋도 고민해보려고 한다.
참고
comments powered by Disqus