Table of Contents
GPU 워크로드를 위한 K8S 스케줄링 전략
K8S 클러스터에서 GPU 워크로드를 운영하다보면, 기존의 vCPU, Memory 와 다르게 GPU 리소스의 특수성 때문에 리소스에 대한 관리방식을 다르게 고민해야한다. 특히 일반적인 리소스와 다르게 GPU 파편화문제가 제일 이슈가 되는데, 이를 해결하기 위한 고민들을 정리해보았다.
문제점 - GPU 파편화
-
하나의 GPU Worker Node 에 할당되는 GPU 리소스의 제한이 있다. - 일반적으로 하나의 GPU Worker Node 에는 NVIDIA GPU 기준 4에서 8 GPU가 최대로 가질 수 있는 리소스 갯수가 된다. (V, A, H 시리즈)
-
GPU Workload 는 이 리소스를 특정 사이즈 만큼 필요로 한다. - GPU Worker Node 에 배치되는 GPU Workload 는 이 리소스를 1/2/4/8 과 같이 2의 배수만큼 필요로 한다.
-
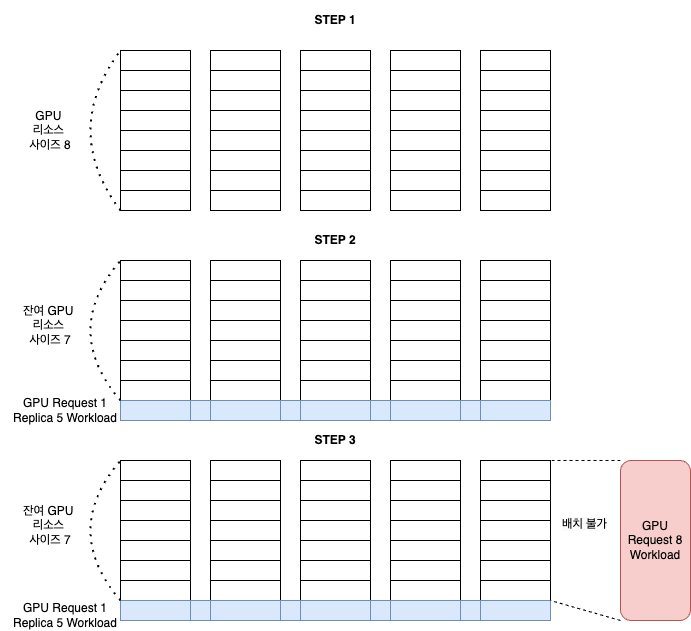
기본 스케줄러는 가능한 골고루 분산 - 만약 GPU Worker Node 가 5개가 있고, GPU 리소스 요구량이 1 GPU이면서 Replica 가 5인 GPU Workload 가 배치된다면, 기본 스케줄러는 이를 골고루 분산하여 개별 Worker Node 가 하나씩의 GPU Pod 을 가지도록 배치한다. (scoring 계산에 따른다.)
-
이제 추가로 GPU 리소스가 8 이 필요한 workload 가 배치되려고 하는 경우, 리소스 8이 비어 있는 노드가 없기 때문에 스케줄링에 실패하게 된다. 하지만 GPU Worker 전체로 보면 아직 여유 리소스 35가 남아 있다.
-
이를 도식화 하면 다음과 같다.
대안
이를 해소하기 위해서는 스케줄링을 다르게 하는 대안을 생각해 볼 수 있다.
1. Bin Packing 스케줄러 도입
Bin Packing 이란?
Bin Packing은 제한된 자원을 최적화하여 사용하는 스케줄링 전략이다. GPU와 같은 제한된 자원을 다룰 때, Pod을 배치할 Node를 가능한 빈틈없이 채워 리소스 사용률을 극대화하기 위해서 사용한다. (bin 은 말 통, 상자라는 의미이다. bin packing은 상자에 물건을 담을 때 차곡차곡 쌓아서 빈공간이 없도록 하는 경우를 떠올려보자.) 쓰레기통이 가득 차면 발로 꾹꾹 눌러 담는 걸 생각하면..
K8S Custom 스케줄러 적용하기
K8S는 별도로 지정하지 않는 경우 default-scheduler 를 사용하여 Pod을 배치한다. k8s 클러스터에 구동중인 기본 pod 중에 하나를 describe 해보면 다음과 같은 내용을 확인할 수 있다.
apiVersion: v1
kind: Pod
metadata:
name: my-sample-pod
...생략...
spec:
schedulerName: default-scheduler # 지정하지 않아도 default-scheduler 가 선택된다.
...생략...
필요하다면, pod 에 scheduler 를 지정할 수 있다는 의미다. 기본 스케줄러가 아닌 별도의 custom scheduler 사용하려면 스케줄링을 결정하는 KubeSchedulerConfiguration 를 등록하면 된다.
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
leaderElection:
leaderElect: true
resourceName: bin-packing-scheduler
resourceNamespace: my-system
profiles:
- schedulerName: bin-packing-scheduler
pluginConfig:
- name: NodeResourcesFit
args:
scoringStrategy: # 어떤 노드에 배치할지 결정하기 위한 scoring 계산 전략을 결정할 수 있다.
type: MostAllocated # MostAllocated 를 선택했다면 가장 많이 사용하고 있는 노드를 선택하라는 의미가 된다.
resources:
- name: cpu
weight: 1
- name: memory
weight: 1
- name: nvidia.com/gpu
weight: 100 # 스케줄링을 위한 score 를 계산할 때 nvidia.com/gpu 타입의 리소스에 대해서 가중치를 100으로 줬다. (cpu/memory 에 비해서 100배 더 중요하게 보겠다는 의미)
이제 bin-packing-scheduler을 등록하고 새로운 pod 를 배치할 때 schedulerName 을 지정하면 ModeAllocated 가 적용된 스케줄링 알고리즘이 적용되어 노드에 배치된다.
apiVersion: v1
kind: Pod
metadata:
name: my-sample-pod-new
...생략...
spec:
schedulerName: bin-packing-scheduler
...생략...
2. Node 그룹 분리 전략
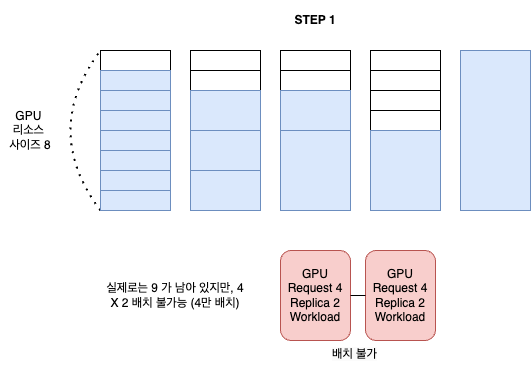
custom scheduler 를 적용하면 문제가 해결될 것 같지만, 그럼에도 빈 공간이 남아서 큰 사이즈의 pod가 배치에 실패하는 경우가 발생한다. 파편화로 스케줄링이 실패하는 케이스는 줄어 들지만, 아예 없어지지는 않는다.
- 여러가지 gpu resource request size 를 가지는 워크로드를 혼합해서 사용하는 경우
- 시간이 지나면서 워크로드가 eviction 되는 시점이 각기 다르기 때문에
- 결국 지나면서 빈 공간이 어중간 하게 남게 되어 사이즈가 큰 pod 이 들어갈 자리가 부족해진다.
- 이를 도식화 하면 다음과 같다.
우리는 한정된 자원만 가지고 있고, 파편화를 완전히 막을 수 없다면 예측 가능성이라도 높이는 추가 전략이 필요하다.
size 가 여러개인 워크로드를 혼합해서 배치하는 경우 특정 size 의 워크로드가 배치되기 쉬운지 어려운지 예측하기가 어렵게 되어 제때 추가 GPU 자원을 수급하기 어렵다. 따라서 아예 사이즈별로 노드그룹을 분리하는 전략을 고민해보았다.
Node Label을 활용해서 그룹 분리
GPU Worker Node에 아예 다음과 같이 custom 한 Nodel label을 부여하여 slot 별로 배치할 수 있는 노드의 종류를 구분했다.
apiVersion: v1
kind: Node
metadata:
name: gpu-cluster-v100-worker001
labels:
my.gpu.cluster/gpu-type: NVIDIA-V100-32GB
my.gpu.cluster/nvidia-gpu-support: 'true'
my.gpu.cluster/node-group: SLOT-4
...생략...
pod 에서는 node label 을 선택하도록 정의하면 된다.
apiVersion: v1
kind: Pod
metadata:
name: my-new-slot-4-pod-sample-1
...생략...
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: my.gpu.cluster/gpu-type
operator: In
values:
- NVIDIA-V100-32GB
- key: my.gpu.cluster/node-group
operator: In
values:
- SLOT-4
...생략...
분리된 Node Group 을 운영하는 방식을 도식화 하면 다음과 같다.
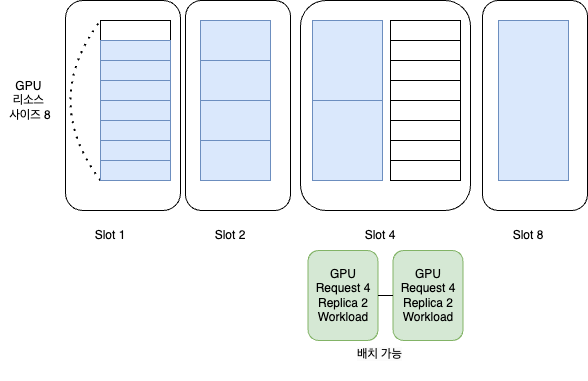
이 전략을 요약하고 장단점을 정리해보면 다음과 같다.
- Slot 별로 남은 자원을 관리한다.
- 장점으로 고정된 사이즈로만 운영하기 때문에 자원 파편화를 막기 수월하다.
- 이에 따라 배치되는 워크로드에 따라 노드 자원의 소비량을 예측하기 쉬워진다.
- 단점으로는 다른 종류의 Slot 으로 운영되는 노드 그룹에 자원이 남아 있더라도 해당 자원을 사용할 수는 없다.
(이 전략을 고려할 때, 재활용 쓰레기를 분리수거할 때 유리는 유리에, 종이는 종이에, 플라스틱은 플라스틱에 버리는 상황이 떠올랐다)
결론
무한의 GPU Worker Node 가 존재한다면 문제는 발생하지 않는다. 하지만 우리의 자원은 유한하고 결국 상황에 맞게 custom scheduler 를 사용하기도 하고, 아예 노드 그룹을 분리해서 사용하기도 한다.
GPU와 같은 리소스를 다루기 전까지는 Custom Scheduler 의 존재조차 인식하지 못했는데, 이런 고민을 하면서 조금 더 K8S에 대해서 알게되었다. 모든 상황의 선택지는 결국 각각의 트레이드오프가 있음을 다시한번 깨닫게 된다.
comments powered by Disqus