Table of Contents
개요
k8s 클러스터를 운영하다보면, 종종 Node Drain 작업을 수행해야하는 경우가 발생한다. 나의 경우에는 GPU 기반의 AI Workload를 운영하는 플랫폼을 개발하고 있는데 특정 Node 의 GPU에 장애가 발생하는 경우에 이 Node 에서 동작중인 pod 을 다른 노드로 옮긴 뒤에 노드를 재부팅하거나 물리적으로 교체하는 작업을 수행했었다. 이 Node Drain 작업시에 종종 Pod 의 위치에 따라 Service 가 불가능한 상황이 발생하여 이를 제어하기 위해서 PodDisruptionBudget을 알아보았다.
Node Drain?
노드 드레인이란 특정 노드에서 동작중인 pod를 다른 노드로 이동시키고, 해당 노드를 스케줄링에서 제외 시켜 새로운 Pod 이 배포되지 못하도록 하는 작업이다.
일반적으로 노드의 메인터넌스 작업이 필요한 경우에 수행하는 명령어라고 할 수 있다. Drain 이란 단어가 ‘물을 빼다’ 라는 의미가 있는데 찰랑거리는 욕조에 마개를 열어 물을 빼는 상황을 생각해보면 이해가 쉽다.
주로 노드의 OS 업데이트, 하드웨어 장애시에 많이 사용하게 된다.
나의 경우에는 AI 플랫폼을 운영하기 위한 GPU worker를 사용하고 있어서, 특정 GPU Ecc 에러가 감지되어 재부팅 해야하거나, 아예 완전히 GPU를 교체해야하는 하드웨어 장애가 발생하는 경우 많이 사용하게 되었다.
명령어는 다음과 같이 노드의 이름을 입력하면 된다.
kubectl drain <NODE_NAME>
드레인 명령어를 입력하면 해당 노드에서 수행중인 pod 이 삭제되어 다른 노드에 다시 스케줄링 된다. 이렇게 노드가 삭제되면 eviction(축출) 되었다고 표현한다 다만 drain 명령어를 실행해도 daemonset 과 같은 pod 는 삭제되지 않는다. 만약 daemonset pod 도 함께 삭제해야한다면 다음과 같이 명령어를 입력하면 된다.
kubectl drain <NODE_NAME> --ignore-daemonsets=false
Node Drain 시에 Service 가 단절되는 상황
pod 이 스케줄링 되어 있는 상황에 따라서 Service 가 단절되는 상황이 발생한다. 다음의 경우를 생각해보자.
- drain 작업을 수행하려는 node 에 pod 가 몰려 있는 경우
- 예를 들어 drain 작업을 수행하려는 node 에 replica size 가 2인 pod 가 모두 스케줄링 되어 있는 경우 drain 작업을 수행하면 서비스가 단절된다.
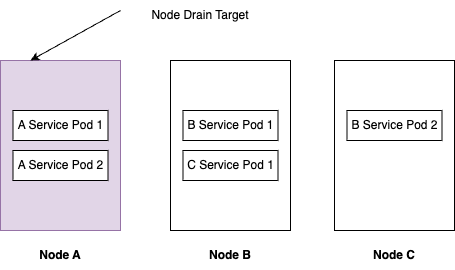
왜 그러한지는 pod 의 eviction 과정을 살펴보면 이해할 수 있다.
Pod Eviction
- 드레인 명령어가 입력되면 먼저 노드는 스케줄링에서 제외어 새로운 pod 이 배치되지 못하도록 한다.
- 그 다음 pod 가 eviction 된다.
- pod 는
terminating상태가 된다. - 참고로 eviction 은 pod의 TerminationGracePeriodSeconds 설정에 따라 종료과정을 거친다.
- preStop 이 설정되어 있다면 이 hook 을 먼저 실행하고 hook 완료시
TERM시그널을 main container 에 전달한다. - TerminationGracePeriodSeconds 안에 완료되지 못하면
SIGKILL시그널이 main container 에 전달된다.
- pod 는
- pod 가
terminating상태임을 감지한 클러스터는 replica 를 유지하기 위해서 신규 pod 를 생성하는데 이미 drain 대상이 된 노드는 스케줄링 제외 되어 있기 때문에 다른 노드에 배치된다.
PodDisruptionBudget 를 사용하여 MinAvailable 조정하기
노드 드레인 작업시 서비스를 유지하기 위해 최소한의 pod 수를 유지해야한다. replica size 가 2라면 1 개의 pod 씩 옮겨야 서비스가 유지된다.
이럴 때는 PodDisruptionBudget 의 MinAvailable 을 조정하면 된다.
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: my-pdb
spec:
minAvailable: 1
selector:
matchLabels:
app: my-gpu-app
최소한 하나의 replica 는 유지하도록 설정하였다.
이렇게 되면 최소한 하나의 pod replica 는 유지되기 때문에 서비스가 단절되는 상황을 방지할 수 있다. replica 2 의 pod 이라면 1 개의 pod 이 유지되고 나머지 pod 이 다른 노드에 스케줄링되기 때문이다.
이와 반대로 MaxUnavailable 을 지정할 수도 있다.
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: my-pdb
spec:
maxUnavailable: 1
selector:
matchLabels:
app: my-gpu-app
이 경우에는 하나씩 다른 노드로 새로운 pod 을 스케줄링 하게 된다.
다만 replica size 가 크다면 하나씩 이동시키는 건 시간이 오래걸리기 때문에 MaxUnavailable 값은 25%와 같이 퍼센트 값을 지정할 수도 있다.
만약 MaxUnavailable 이 0 이라면?
pod 의 eviction 을 생각할 때 MaxUnavailable 이 0 이라면 eviction 이 차단된다. 따라서 노드 드레인 작업이 완료되지 않는다. 따라서
해당 노드에 위치한 pod 를 옮기기 위해서 다른 방법을 사용해야한다.
노드에서 pod 를 제거하는 다른 방법
PodDisruptionBudget을 생각하지 않고 특정 노드에 스케줄링되어 동작중인 pod 를 다른 노드로 옮기는 다른 방법은 해당 노드를 먼저 스케줄링에서 제외하고
동작중인 pod 가 포함된 deployment 를 rollout restart 하면 된다. 이 방법도 많이 사용한다.
다만 이렇게 하면 deployment 의 replica count 가 많은 경우 다른 노드에 스케줄링된 모든 pod 이 새롭게 스케줄링 되어야 하므로
node drain 보다 시간이 오래걸리고, node 에 위치한 여러 pod 모두 작업을 해주어야 해서 번거롭다.
상황에 맞게 선택해서 사용하도록 하자.
결론
- k8s 클러스터를 운영할 때 node drain 과정에서 replica 에 따라서 서비스가 중단되는 경우가 발생할 수 있다.
- 이를 방지하기 위해서
PodDisruptionBudget를 설정할 수 있고, 상황에 따라MinAvailable또는MaxUnavailable를 설정해서 사용하면 된다. - Pod Eviction 과정에 대해서 이해하는 것이 좋다.
- 상황에 따라 노드를 스케줄링 제외하고 deployment rollout restart 로 pod 를 다른 노드에 이동시키기도 한다.
참고자료
- https://kubernetes.io/docs/tasks/run-application/configure-pdb.
- https://blog.gruntwork.io/gracefully-shutting-down-pods-in-a-kubernetes-cluster-328aecec90d
- https://stackoverflow.com/questions/75385965/when-using-kubectl-drain-node-node-pods-it-doesnt-wait-for-new-pods-to-get-h
comments powered by Disqus