k8s 환경에서 pod를 배포할 때 순간적으로 5XX 에러가 발생하는 경우가 있다. 별다른 문제가 아니라고 생각할 수도 있지만,
배포가 진행될 때마다 사용자 중 일부가 오류를 경험할 수 있기 때문에, k8s 옵션을 적절하게 설정하여 5XX에러를 줄이는 것이 좋다.
deployment yml 설정에서 이런 옵션들을 살펴보고 안전하게 pod를 종료/시작하는 방법을 살펴보았다.
Step1. 기본적인 Deployment
k8s 환경에서 배포를 위한 방법은 여러가지가 있지만 기본적인 Deployment Yml 은 다음과 같은 형태라고 가정해보자.
기본적인 Deployment 설정을 하고 나면 배포할 때 마다 순간적으로 5XX 오류를 확인할 수 있다. 이유는 POD는 시작하자마자 트래픽을 처리할 수 없기 때문이다.
POD가 정상적으로 트래픽을 받을 수 있는지 없는지 확인하기 위해서 Probe 설정을 추가해보자.
K8S deployment
Step2. Probe 설정
기본적인 Deployment 설정을 했다면 Probe 설정을 추가해야한다.
livenessProbe : 컨테이너가 정상적으로 동작중인지 확인하는데 사용한다. 주로 HTTP 요청을 보내서 응답 결과가 정상적으로 200OK 가 반환되는지 확인해서 동작 유무를 판단한다. 응답이 200OK가 아니라면 k8s 클러스터는 pod를 죽이고 재시작하게 된다. 설정하지 않으면 기본값이 Success 로 간주된다.
readinessProbe : 컨테이너가 시작할 때 요청을 받을 준비가 되었는지 확인하는데 사용한다. 응답이 200 OK 가 아니라면 k8s 클러스터는 이 pod에 트래픽을 전달하지 않는다. 설정하지 않으면 기본값이 Success 로 간주한다.
readinessProbe:
httpGet:
path: /actuator/health/liveness #굳이 actuator 경로를 쓸 필요는 없다.port: 8080timeoutSeconds: 3# 타임아웃 시간 설정periodSeconds: 30# 확인 주기successThreshold: 1#성공 기준 횟수failureThreshold: 5#실패 기준 횟수livenessProbe:
httpGet:
path: /actuator/health/readiness #굳이 actuator 경로를 쓸 필요는 없다.port: 8080timeoutSeconds: 3periodSeconds: 30successThreshold: 1failureThreshold: 5
Probe 라는 건 중학교 건전지 회로 실험에서 사용해보았던, 전류가 흐르는지 확인하는 도구라고 생각하면 이해가 쉽다. 탐침, 조사하다는 의미로 해석할 수 있다.
오늘쪽 바늘 모양 도구가 probe
pod 가 실행되어 rediness 가 success 가 되더라도 바로 트래픽을 전달받으면 안되는 상황이 있을 수 있다. Spring 과 같은 경우에는
애플리케이션 내부에서 일종의 Warm up (애플리케이션이 구동하기 위한 준비 작업들)이 더 필요할 수도 있기 때문이다.
특히 단순히 redinessProbe를 path: /_probe/readiness 와 같이 설정한뒤에 200 OK를 반환하는 형태로 설정해둔 경우라면 트래픽의 일부가 여전히 오류를 반환할 수 있다.
이런 경우에는 initialDelaySeconds 를 설정할 수 있다.
@GetMapping(value ="/_probe/readiness")
public ResponseEntity<String>healthCheck() {
return ResponseEntity.ok().body("ok");
}
Step 3 initialDelaySeconds 설정
readinessProbe:
httpGet:
path: /actuator/health/readiness #굳이 actuator 경로를 쓸 필요는 없다.port: 8080initialDelaySeconds: 10timeoutSeconds: 3periodSeconds: 30successThreshold: 1failureThreshold: 5livenessProbe:
httpGet:
path: /actuator/health/liveness #굳이 actuator 경로를 쓸 필요는 없다.port: 8080initialDelaySeconds: 10timeoutSeconds: 3# 타임아웃 시간 설정periodSeconds: 30# 확인 주기successThreshold: 1#성공 기준 횟수failureThreshold: 5#실패 기준 횟수
initialDelaySeconds 를 설정하면 pod 가 생성되고 난 뒤에 딜레이를 줘서 pod 가 트래픽을 처리할 준비가 된 후에 응답을 반환할 수 있게한다.
하지만 여기서 끝내면 안되고 한가지 작업이 더 남았다. 바로 종료시점에 대한 고려가 필요하다. pod 가 준비되고 트래픽을 처리하기 까지는 위의 설정으로도 충분하지만,
pod 가 종료될 때 즉각적으로 pod를 제거해버리면, 처리하고 있던 응답을 완료하기 전에 프로세스가 종료되어 사용자가 5XX 에러를 볼 수 있다. 이를 막기 위해서
preStop 설정을 추가해보자.
preStop 설정을 추가하면 Pod 가 종료를 처리할 때 즉각적으로 종료하지 않고 preStop 에 설정된 명령을 수행한 뒤에 pod 종료를 수행한다.
따라서 위와 같이 약 10초의 딜레이를 주어서 현재 처리중이던 응답을 반환할 충분한 시간을 주면 사용자에게는 5XX에러 상황이 발생하지 않을 수 있다.
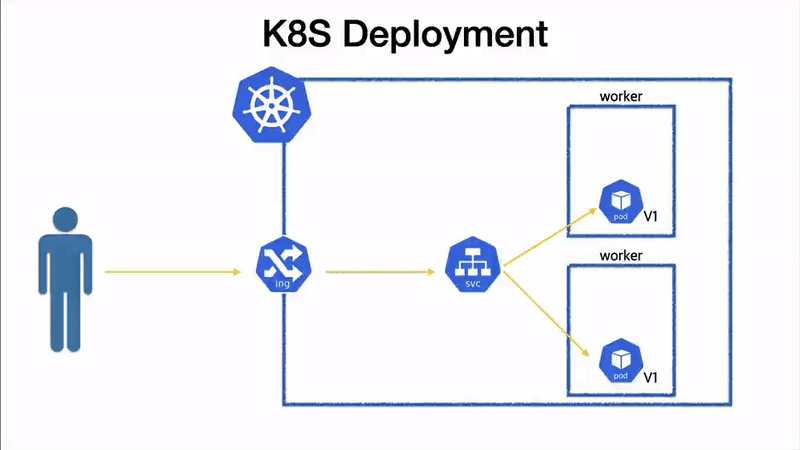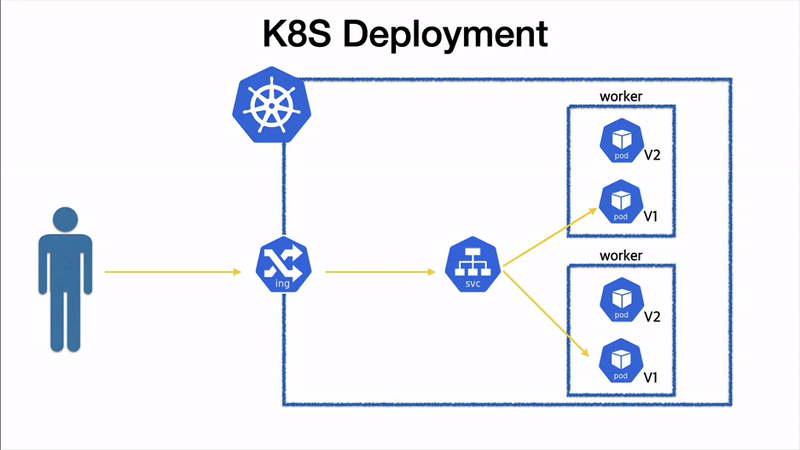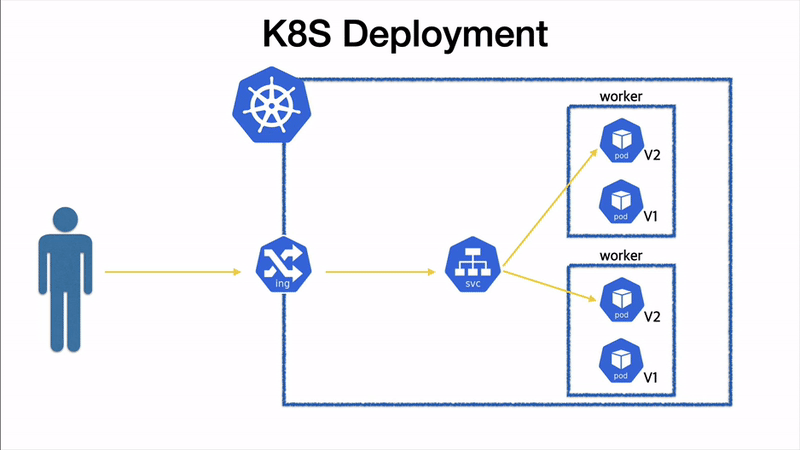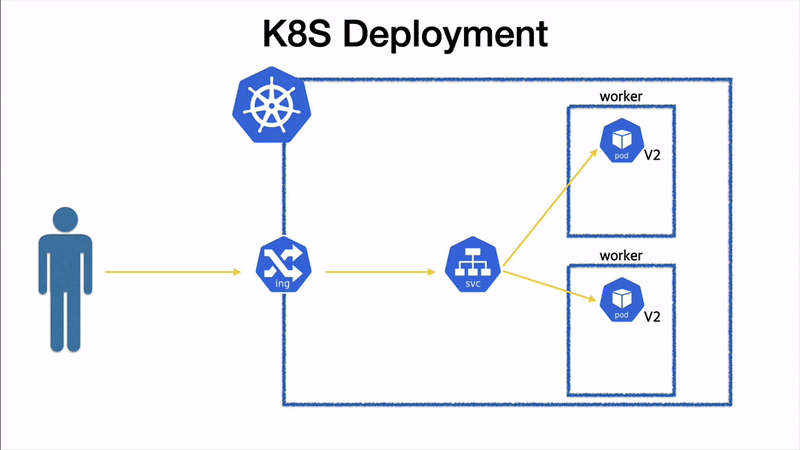
전체 시퀀스 도식화
말로만 하면 이해가 잘 안될것 같아, 그림으로 도식화 해보았다.
전체 pod 전환 순서
최종 yml 파일
최종적으로 production 에서 사용하는 deployment yml 파일음 다음과 같은 형태를 가지고 있다.
K8s에서 pod를 배포하는 과정에서는
pod 가 시작할 때 준비과정(rediness), warmup (initialDelay)에 대한 고민이 필요하고
pod 가 종요할 때 처리하던 응답을 정상적으로 반환할 때까지 기다리기 위한 preStop 과 같은 설정이 필요하다.
이를 잘 이해하고 사용한다면 배포과정에서 사용자가 5XX 에러를 확인하는 일은 없을꺼라고 생각한다.
참고자료
보다 정확한 내용을 이해하려면 pod 의 라이프사이클에 대한 이해가 필요하다. 다음의 참고자료에서 관련 내용을 확인할 수 있다.